
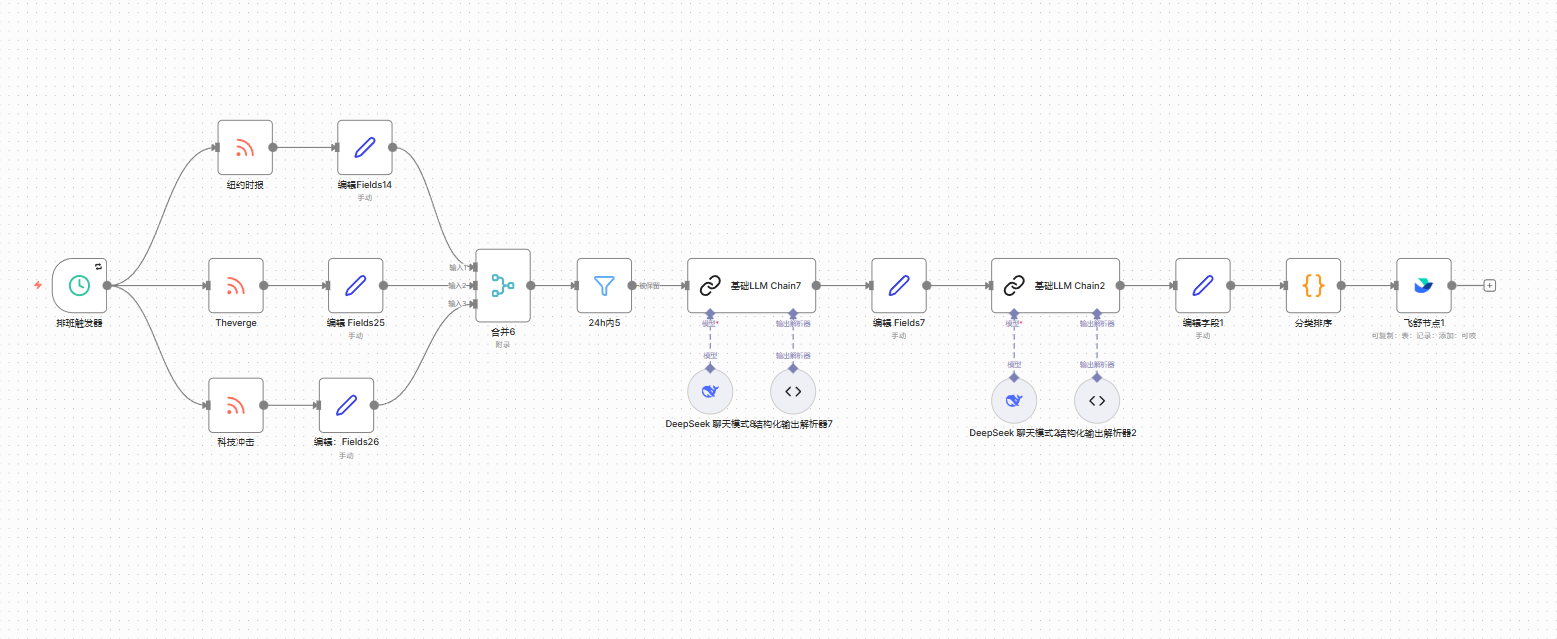
本工作流的主要功能是从多个科技新闻源(RSS)抓取文章,经过筛选,利用 DeepSeek 大模型进行两次处理(可能是总结摘要、翻译或提取关键信息),最后格式化并推送到飞书多维表格中
节点搭建流程:
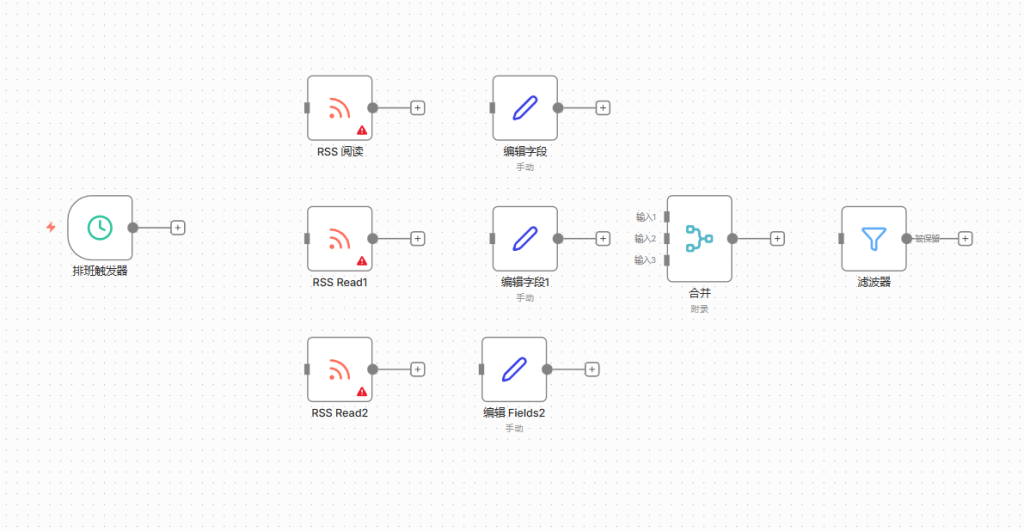
这一步的目的是定时获取新闻,并给不同来源的数据打上标签。
1.添加 Schedule Trigger (定时触发器)
- 设置: 设置为你希望运行的频率(例如每 1 小时或每天早上 8 点)。
2.添加 3 个 RSS Feed Read 节点 (并行分支)
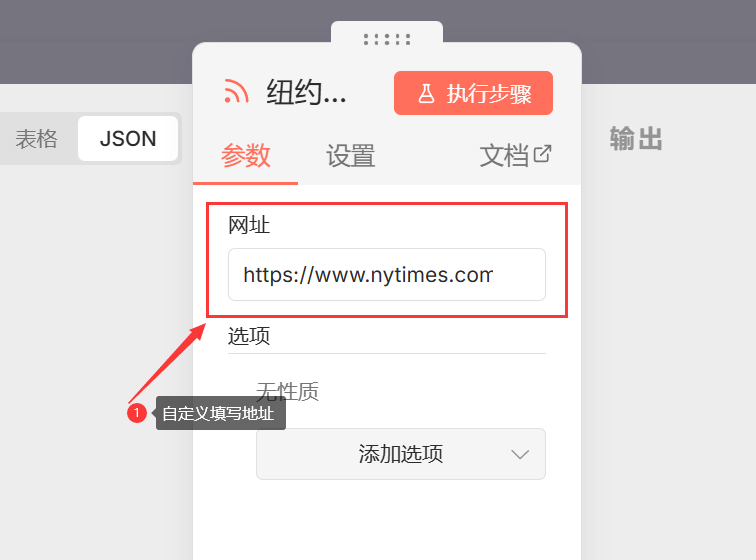
- 分别填入三个新闻源的 RSS 地址:这里是不同的RSS合集,【中文优质RSS集合】
- 上路: 纽约时报 (The New York Times)https://www.nytimes.com/svc/collections/v1/publish/https://www.nytimes.com/spotlight/artificial-intelligence/rss.xml
- 中路: The Verge:https://www.theverge.com/rss/ai-artificial-intelligence/index.xml
- 下路: TechCrunch:https://techcrunch.com/category/artificial-intelligence/feed/
3.添加 3 个 Edit Fields (字段编辑) 节点
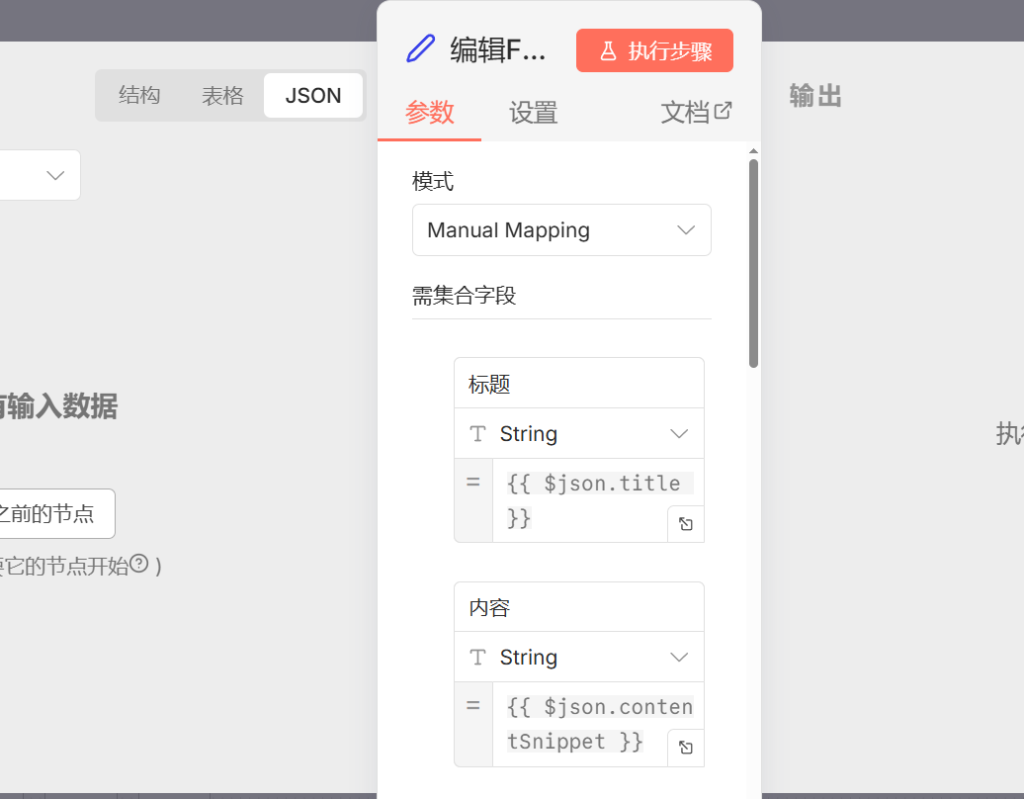
- 分别连接在三个 RSS 节点之后。
- 目的: 为每个分支的数据添加一个来源标签便后续分辨文章来源,3个Edit Fields都一样的
- 标题 String {{ $json.title }}
- 内容 String {{ $json.contentSnippet }}
- 日期 String {{ $json.isoDate }}
- 链接 String {{ $json.link }}
- 来源 String 纽约时报
- 板块 String 新闻
- 分类 String
4.添加 Merge (合并) 节点
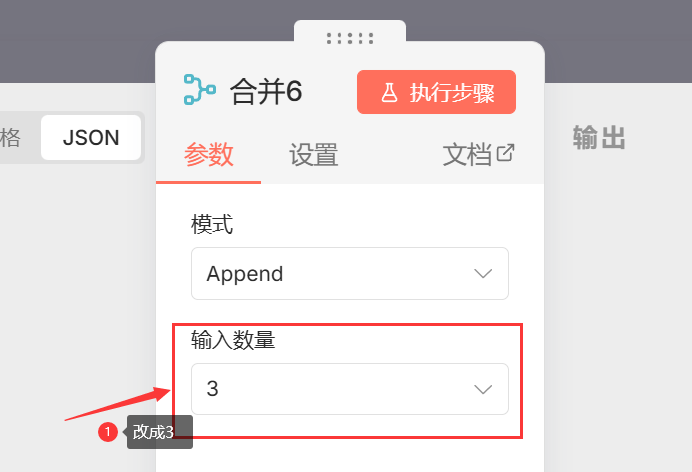
- 连接: 将前面 3 个 Edit Fields 的输出全部连到这个节点的输入端。
- 设置: Mode 选择 “Append” (追加模式),将三路数据合并成一个列表。
5.添加 Filter (过滤器) 节点
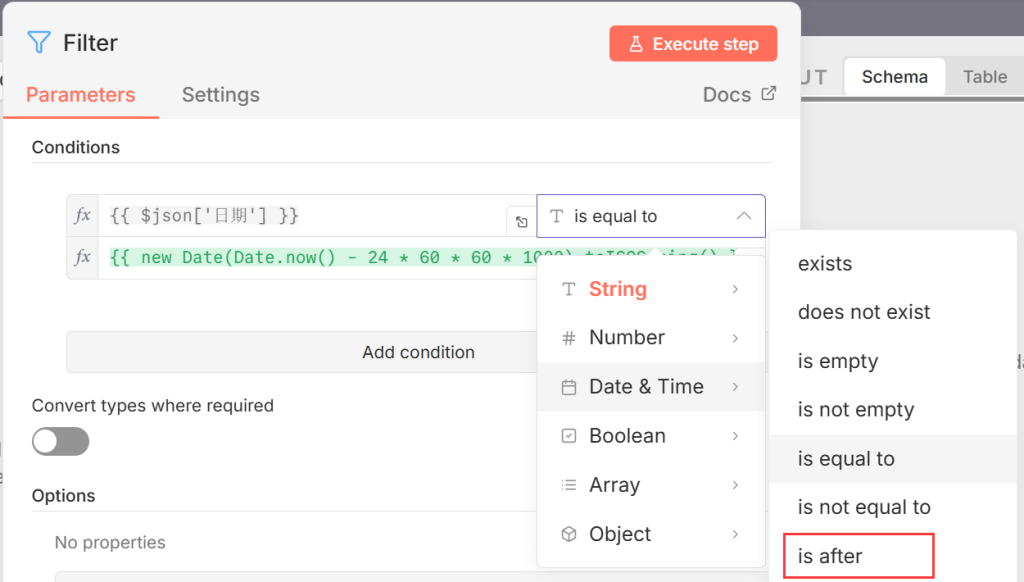
- 连接: 连在 Merge 之后。
- 设置: 设定筛选条件(根据截图上的 “24h内”)
- 条件逻辑:{{ $json[‘日期’] }}
- {{ new Date(Date.now() – 24 * 60 * 60 * 1000).toISOString() }}
- if after
- 注意填写好之后:“打开Convert types where required下的开关”
第二阶段:AI 智能处理 (中间核心部分)
这里使用了 LangChain 的结构,分两轮对文章内容进行深加工。
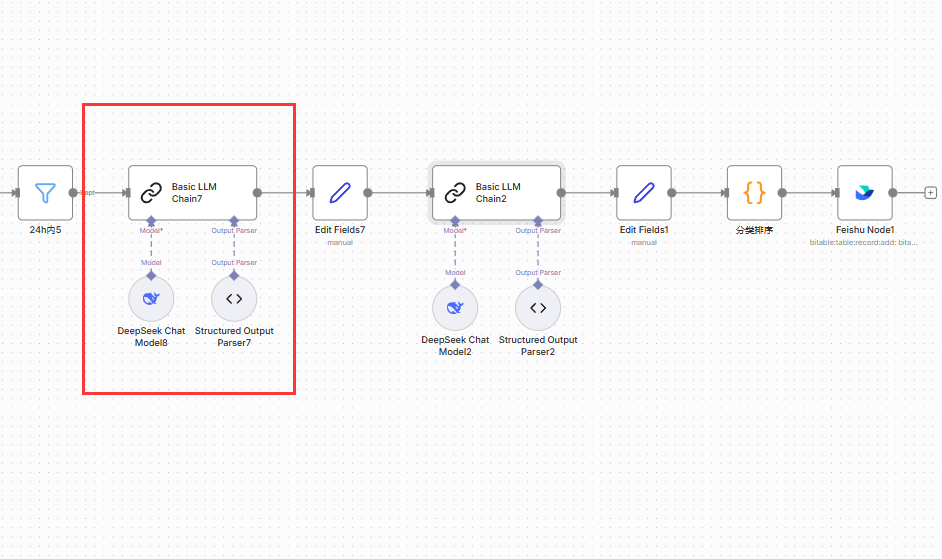
搭建第一组 AI 处理链
6.主节点: 添加 Basic LLM Chain 节点。
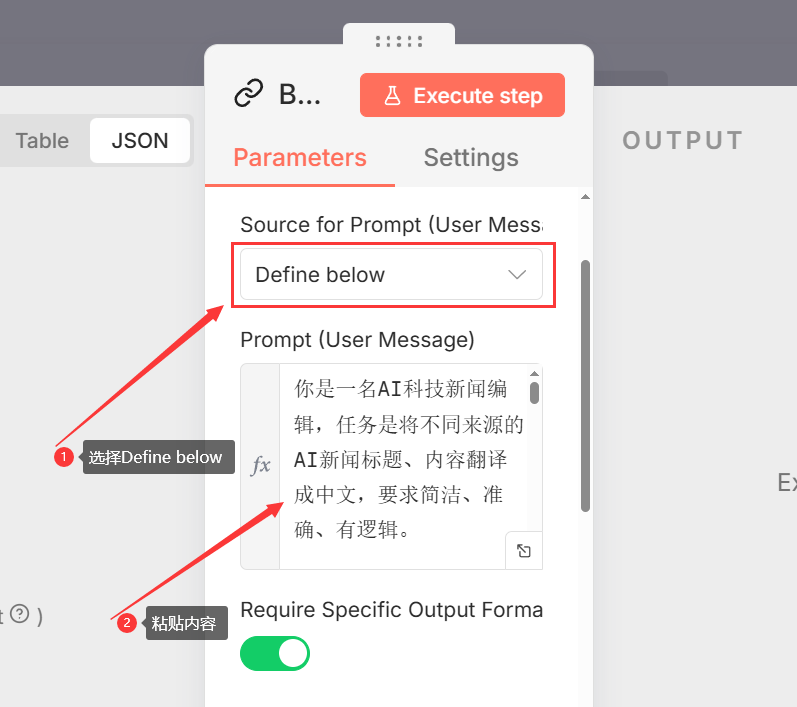
- 挂载模型 (Model): 拖入 DeepSeek Chat Model 节点(如果 n8n 没有原生 DeepSeek,通常使用 OpenAI Chat Model 节点,并将 Base URL 改为 DeepSeek 的 API 地址),连接到 Chain 的 Model 接口。
- 挂载解析器 (Output Parser): 拖入 Structured Output Parser,连接到 Chain 的 Output Parser 接口。这用于强制 AI 输出 JSON 格式()。
- Prompt 设置: 在 Chain 节点中编写提示词,例如:“请总结这篇文章的核心内容…”。
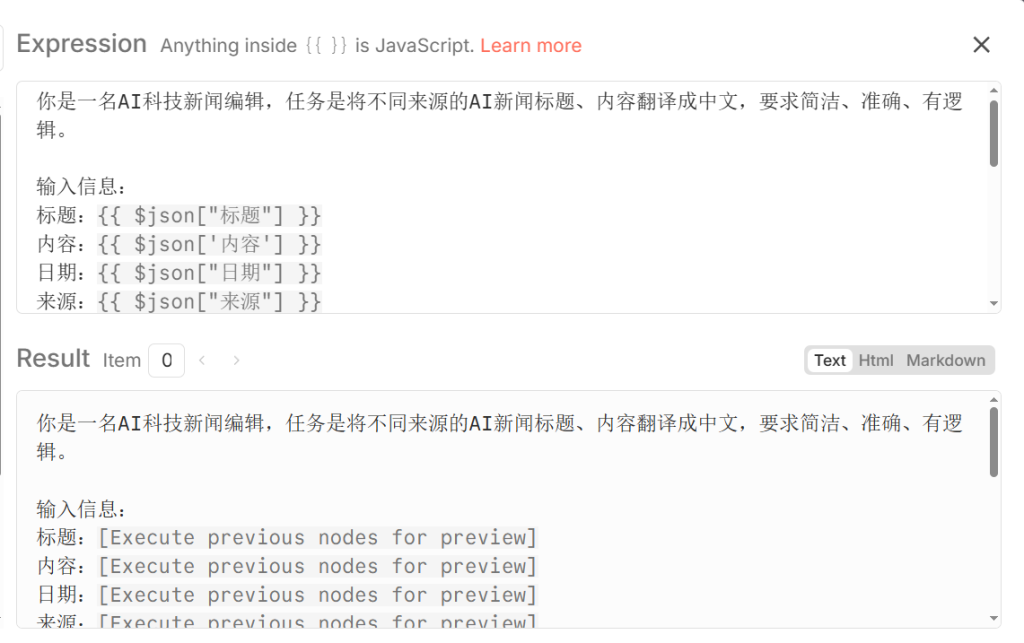
注意:Basic LLM Chain 里面的节点内容你可以人GPT帮你写
7.添加 Edit Fields 节点,跟前面的节点一样这里最后分类里面添加:{{ $json.output[“分类”] }}
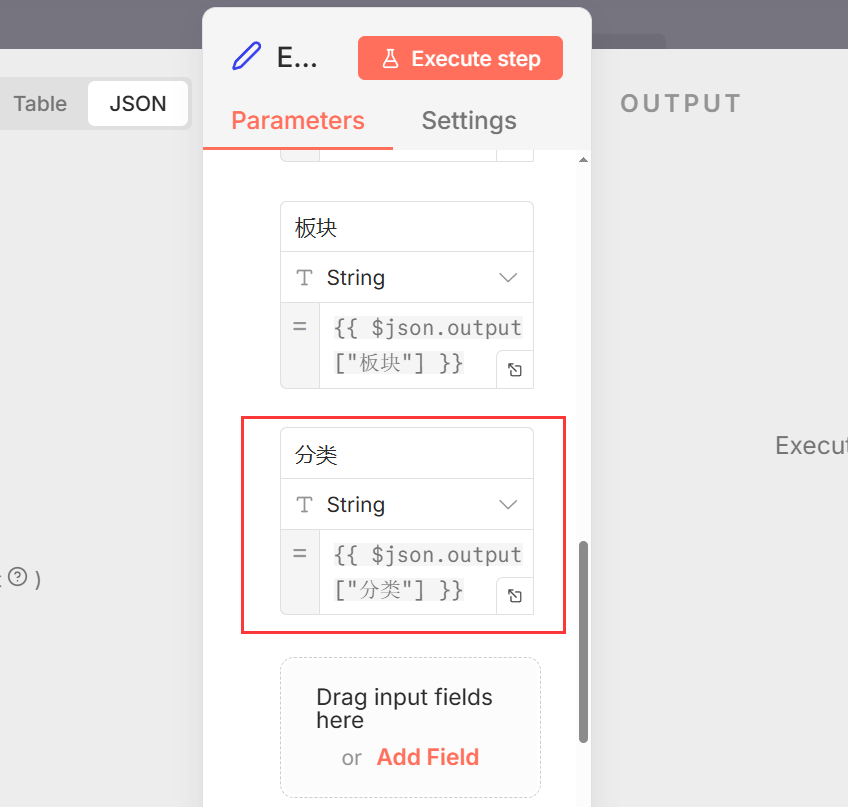
- 目的: 清洗或格式化第一轮 AI 输出的数据,为下一轮做准备。
8.搭建第二组 AI 处理链
- 主节点: 再次添加 Basic LLM Chain 节点。
- 挂载模型 & 解析器: 同样挂载 DeepSeek Chat Model 和 Structured Output Parser。
- Prompt 设置: 这里可能是做深层次处理,比如“将摘要翻译成中文”或者“根据内容判断行业分类、打分”等。
9.添加 Edit Fields 节点,这里的节点跟上面一个,一样不需要改
- 目的: 将 AI 处理后的最终结果整理成飞书表格需要的字段格式。
第三阶段:逻辑处理与输出
10.添加 Code (代码) 节点
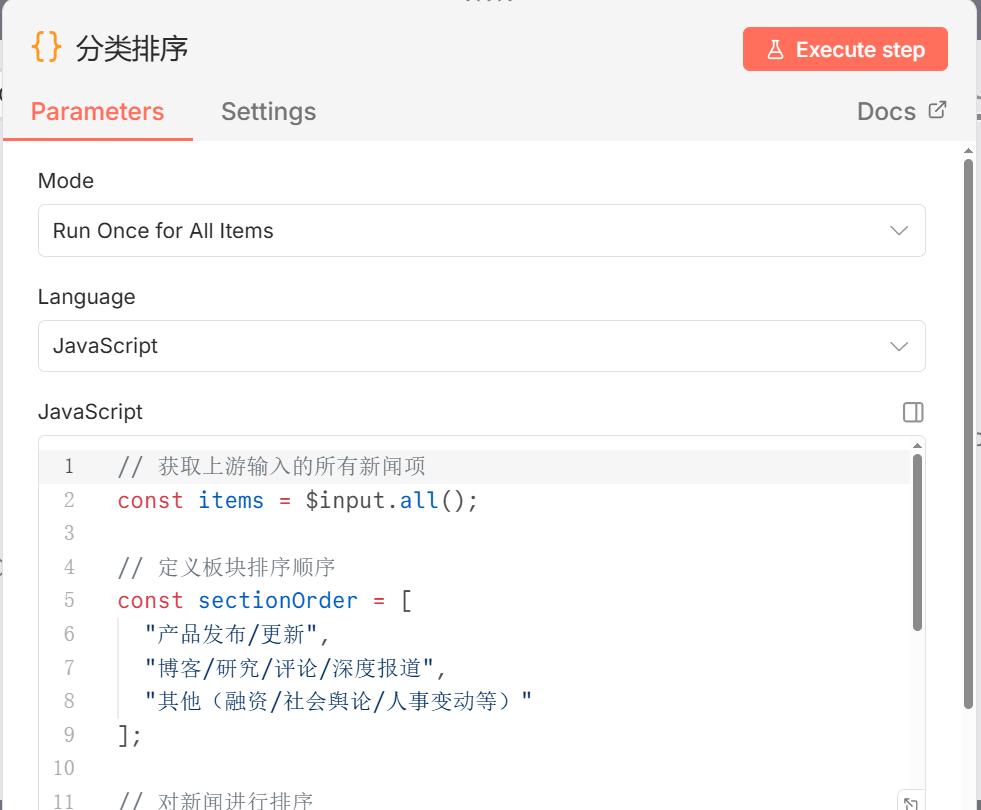
- 标签: “分类排序”
- 目的: 使用 JavaScript 对最终的新闻列表进行排序(例如按重要性打分排序)或者进行最后的数据清洗。
// 获取上游输入的所有新闻项
const items = $input.all();
// 定义板块排序顺序
const sectionOrder = [
“产品发布/更新”,
“博客/研究/评论/深度报道”,
“其他(融资/社会舆论/人事变动等)”
];
// 对新闻进行排序
items.sort((a, b) => {
const sectionA = a.json.分类 || “”;
const sectionB = b.json.分类 || “”;
const indexA = sectionOrder.indexOf(sectionA);
const indexB = sectionOrder.indexOf(sectionB);
return indexA – indexB;
});
return items;
11.添加 Feishu (飞书/Lark) 节点,这里需要添加Token.和ID,还需要添加请求体JSON
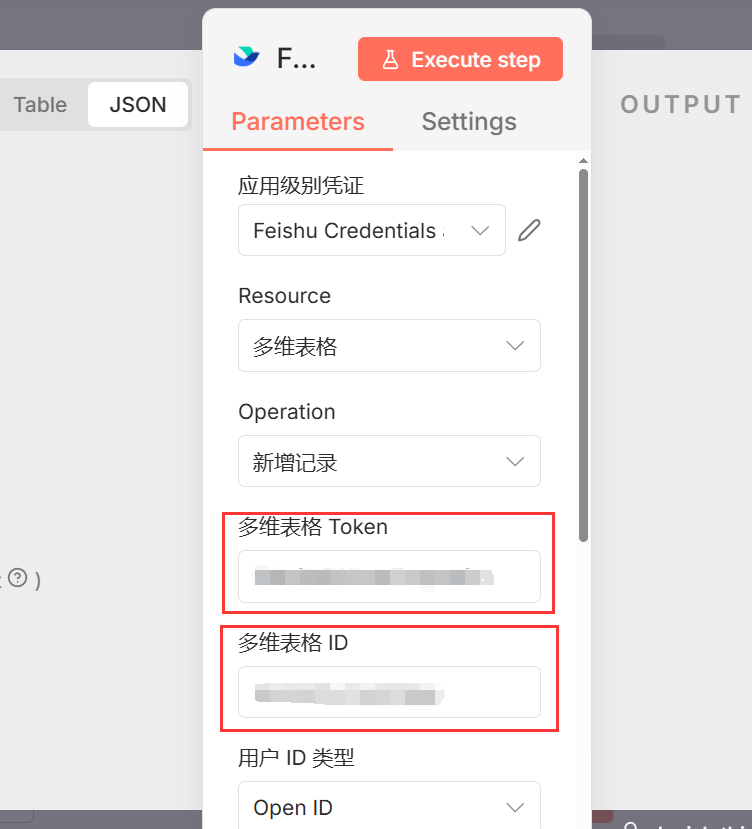
- 连接: 连在 Code 节点之后。
- 设置:
- Resource: Base (多维表格)
- Operation: Create Record (新增记录)
- 映射字段: 将前面处理好的 标题、摘要、来源、URL、AI 评分 等字段,一一对应填入飞书多维表格的列中。
请求体JSON:
{
“fields”: {
“标题”: “{{ $json[‘标题’] }}”,
“内容”: “{{ $json[‘内容’] }}”,
“日期”: “{{ $json[‘日期’] }}”,
“链接”: “{{ $json[‘链接’] }}”,
“来源”: “{{ $json[‘来源’] }}”,
“板块”: “{{ $json[‘板块’] }}”,
“分类”: “{{ $json[‘分类’] }}”
}
}
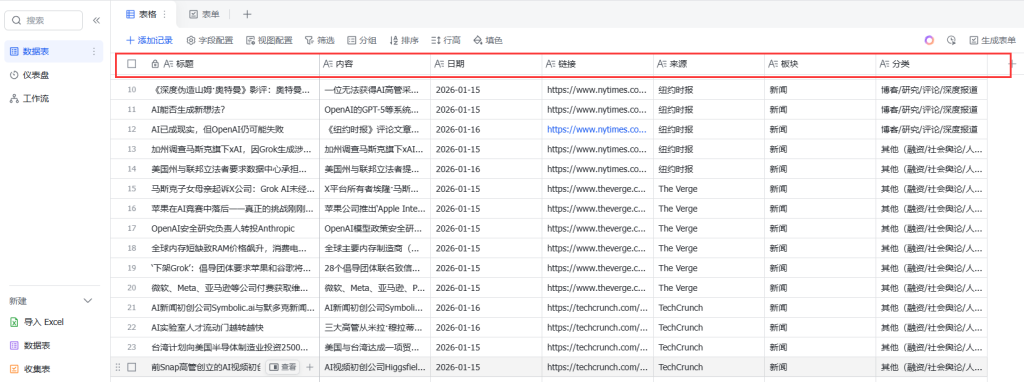
记得在飞书里面这样配置:
关键配置提示 (DeepSeek 接入)
截图中的 “DeepSeek Chat Model” 如果你在 n8n 的节点库里找不到同名原生节点,通常是这样配置的:
- 使用 OpenAI Chat Model 节点。
- 点击 Credentials -> Create New -> OpenAI API。
- 在配置里:
- URL (Base URL): https://api.deepseek.com (或其他 DeepSeek 兼容地址)
- API Key: 填入你的 DeepSeek API Key。
4.在节点模型名称 (Model Name) 里手动输入:deepseek-chat 或 deepseek-coder。
这套工作流非常高效,能把原本需要几小时阅读的科技新闻,自动浓缩成一份高质量的中文日报发到你的飞书里。
如果在搭建的过程中遇到任何问题,请评论区留言,这是整个工作流的前半部分,下面还有两大部分我们下期接着讲,我也会把完整版工作流分享给大家