
本次模型部署适合低显卡用户群体,即便你只有6G显卡也可以轻松本地部署,真正意义上的实现token自由,接下来就跟着我的步骤三分钟完成本地模型部署加实测。本次教程参考零度解说博主
- 第一步下载越狱版模型【下载模型】根据自己电脑配置下载这里以8G以内显卡做演示
- 第二步下载llama.cpp【下载llam.cpp】直接解压即可
- 第三步在外面刚刚解压出来的llama.cpp中创建一个bat可执行程序放入以下代码
- 第四步我们还需要在在llama.cpp里面创建一个models文件夹这里放我们的模型
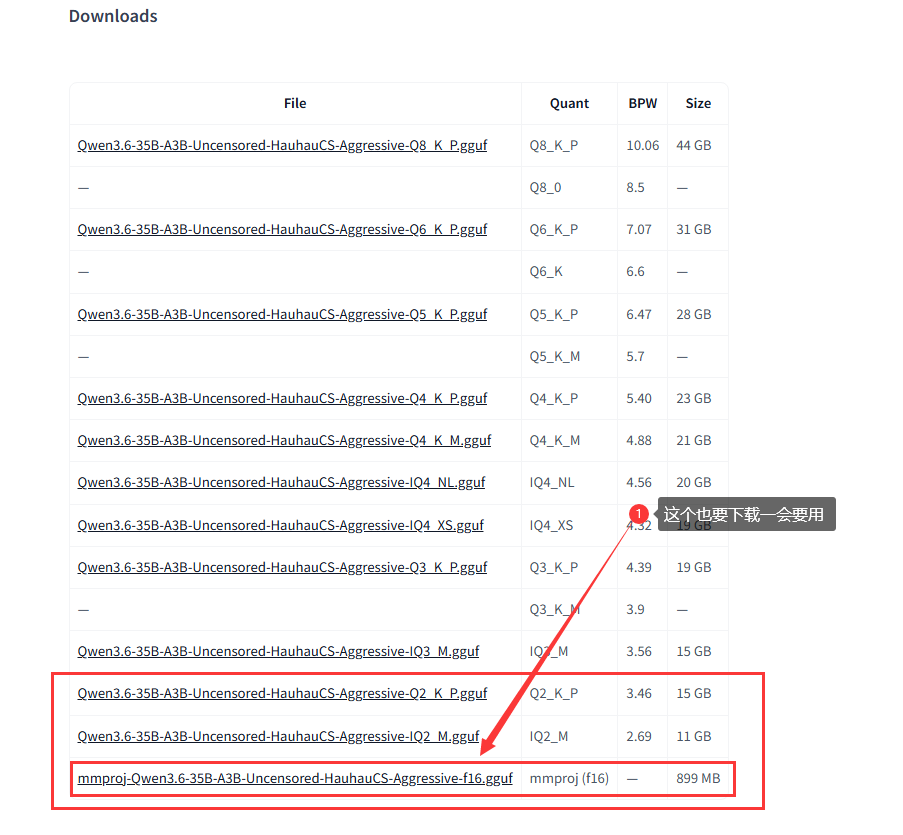
下载模型这里选择模型是适合8G以内显卡
来到下载模型页面选择适合自己的操作系统,这里选择的是windows系统,下面这两个就是适合我们8G显卡的用户使用,直接下载,你可以选择11G或者15G都可以,只要你的显卡是8G,6G就选择11G即可,最下面这个是视觉模型必须要下载,接下来我们就可以开始了。
第二步下载llama.cpp
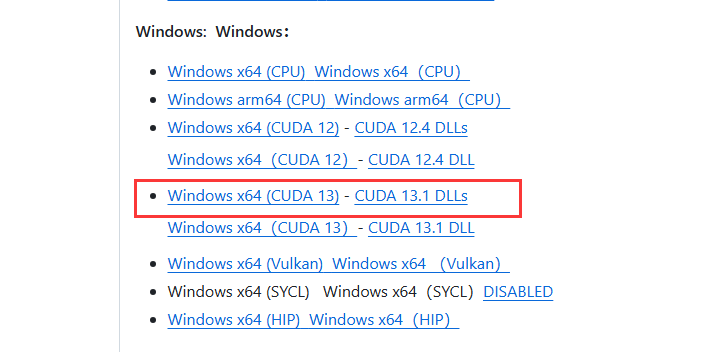
这里注意了我们下载的llama.cpp是一个压缩包,不要在桌面解压,你可以放在你是除C盘以外的盘中,解压之后我们就可以看到这些文件,我们在里面创建一个models文件夹,把我们下载好的模型放到这里面,
第三步在外面刚刚解压出来的llama.cpp中创建一个bat可执行程序放入以下代码
接下来就是我们需要在里面创建一个可执行程序,后缀名改成.bat代码就使用下面的,复制代码粘贴到记事本改后缀名.bat随便起个名字即可
@echo off
chcp 65001 >nul
title Qwen3.6-35B-A3B 越狱版
cd /d "%~dp0"
:menu
cls
echo ==========================================
echo Qwen3.6-35B-A3B 越狱版+多模态模型
echo 零度优化版
echo ==========================================
echo.
echo 1. Q4_K_P(4090 推荐)
echo 2. Q4_K_M(稳定版)
echo 3. IQ4_NL(高压缩高质量)
echo 4. IQ2_M(6G/8G 显卡)
echo.
echo ==========================================
set /p choice=请输入数字:
if "%choice%"=="1" (
llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_P.gguf" ^
--mmproj "models\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
-ngl 999 ^
-c 131072 ^
-n 8192 ^
--host 127.0.0.1 ^
--port 8080
)
if "%choice%"=="2" (
llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf" ^
--mmproj "models\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
-ngl 999 ^
-c 131072 ^
-n 8192 ^
--host 127.0.0.1 ^
--port 8080
)
if "%choice%"=="3" (
llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-IQ4_NL.gguf" ^
--mmproj "models\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
-ngl 999 ^
-c 131072 ^
-n 8192 ^
--host 127.0.0.1 ^
--port 8080
)
if "%choice%"=="4" (
llama-server.exe ^
-m "models\Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-IQ2_M.gguf" ^
--mmproj "models\mmproj-Qwen3.6-35B-A3B-Uncensored-HauhauCS-Aggressive-f16.gguf" ^
-ngl 999 ^
-c 8192 ^
-n 4096 ^
--host 127.0.0.1 ^
--port 8080
)
pause接下来就是测试我们点击bat可执行程序
这里使用的是零度解说提供的脚本,点击之后我们打开终端就可以选择自己的显卡配置,接下来你就可以看到一条URL复制之后在浏览器打开就可以使用。
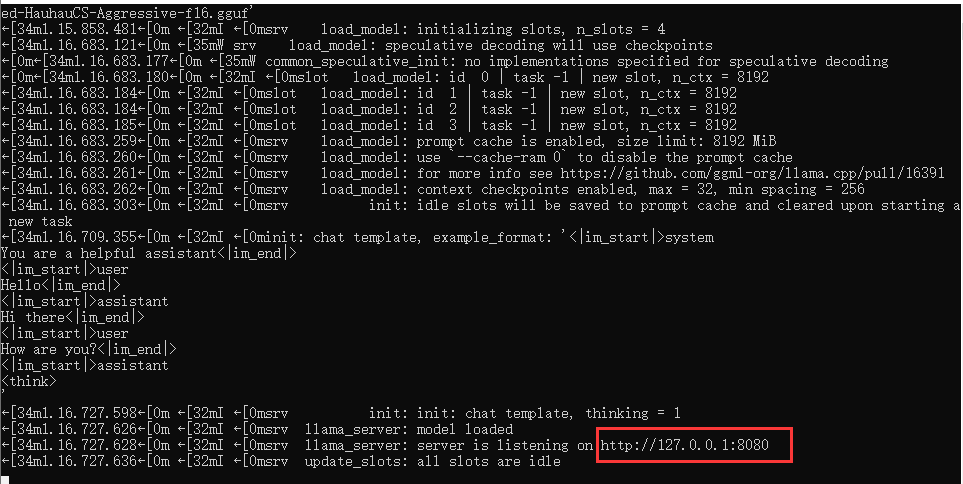
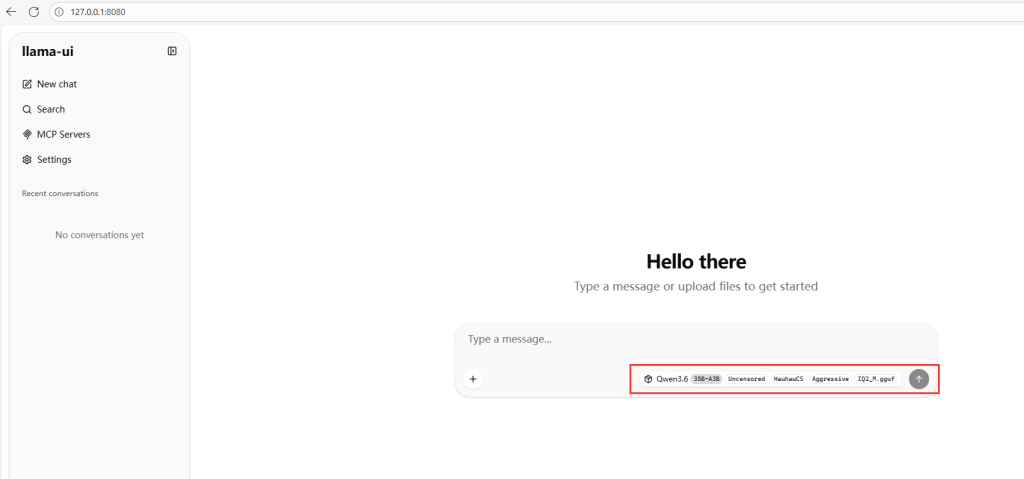
打开浏览器我们就可以看到
当你看到这个界面就怎么我们可以开始使用了,你已经成功完成本地部署大模型,在这里就可以提问了,有兴趣的朋友可以去尝试,部署成功之后还可以对接很多AI工具,真正实现了TOKEN自由,自己做测试完全可以,速度还是非常快的,我这里选择的是11G模型,使用的是8G显卡,测试之后结果还是非常满意的,主要是这次的本地部署非常简单实用,对于新手非常友好
最后补充说明
如果你想理解更多关于最新AI工具使用的,请给我留言,我会亲自测试之后,做最简化的处理,让更多的新人也可以快速学习掌握使用它