
最近字节跳动同时推出了两款定位截然不同的王牌模型:国内国内很多用户吸引,甚至超越了最新出来的sora2,首先我们要说的就是Seedance 2.0 Fast,Seedance 2.0 Fast 专攻视频生成,追求极致的生成速度;而Seedream 4.5则深耕图像创作,致力于将AI绘图从“创意玩具”转变为“生产力工具”。它们共同构成了字节跳动在AI内容创作领域的“视频+图像”双引擎战略,目前Seedance 2.0 Fast,可以在豆包,即梦使用
Seedance 2.0 Fast
使用非常简单,最大支持15s,长视频,打开即梦,或者豆包APP,选择模型。直接给它剧本内容就可以自动生成,速度非常快,这里我使用的是网页版,app里可以上传自己的分身,就跟sora2一样,我发现Seedance 2.0 Fast模型生成的视频,比sora2要快画质方面也几乎超越了前者,使用sora2制作视频,对于国内很多人来说有门槛,首先就是需要上网环境,这次Seedance 2.0 Fast模型的出现,直接给国内的用户上了高速公路,而且是免费试用,每天可以使用豆包生成6条视频,即梦我目前还没有测试,我在使用豆包测试的效果还是非常出色的
对于刚接触AI创作的新手而言,理解这两款模型的核心差异与适用场景,是高效开启创作之旅的第一步。本文将为你详细拆解它们的功能特性、使用教程与实战技巧
Seedream 4.5
与追求速度的Seedance 2.0 Fast不同,Seedream 4.5 是字节跳动在2025年第四季度推出的AI图像生成与编辑模型,它的目标是解决设计师和创作者在商业级图像生产中的核心痛点
三大核心突破
Seedream 4.5的升级聚焦于实用性与可控性:
精准的参考图理解与保持:能严格遵循参考图的细节(形状、比例、颜色、材质),生成的新图能最大化保持原图特征,非常适合电商产品图变体或角色设计延展。
强大的多图融合与编辑能力:支持基于多张参考图进行风格、元素的融合创作,或对单张图进行精准编辑(如换装)。
专业级的文字排版与组图生成:在商业视觉、人像、产品图方面表现极强,能生成结构稳定、小字清晰的商业广告级图像,并支持基于一张图生成一组内容关联的图像(组图生成)
我发现Seedream 5.0 Lite已经出来了,官方给的活动价格在2026年2月28号前开通,免费使用Seedream 5.0Lite
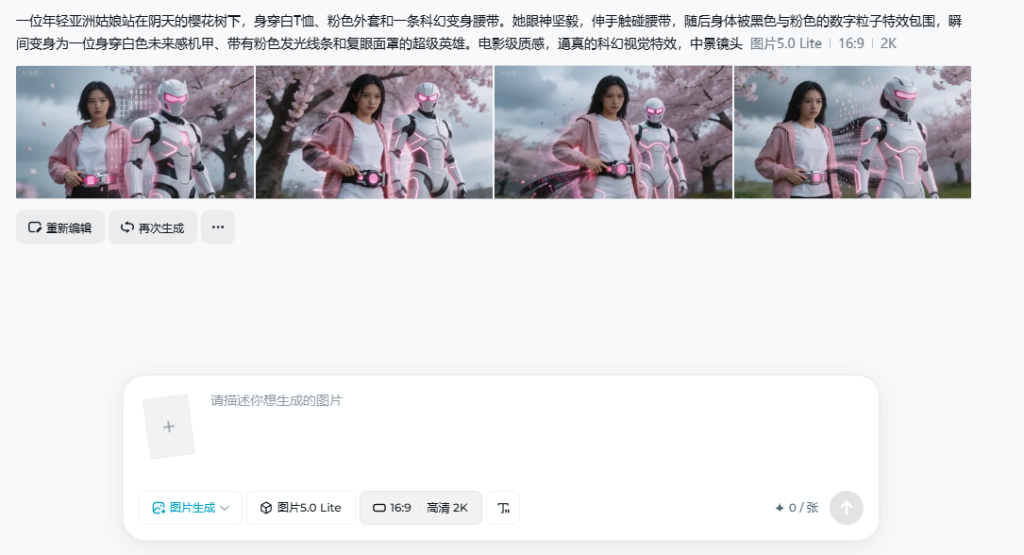
这是使用Seedream 5.0 Lite,生成的效果,清晰度,非常高,AI的理解能力也非常精准
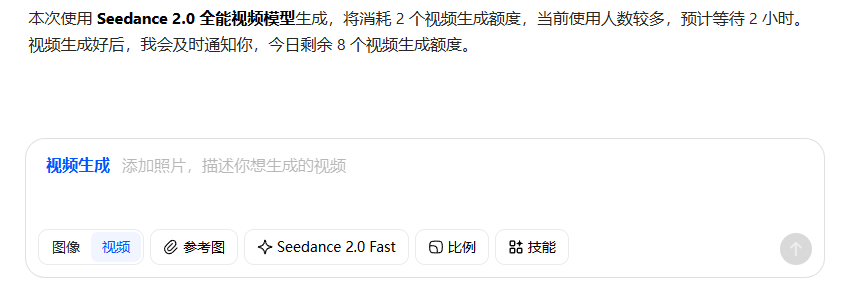
在使用Seedance 2.0 Fast生成视频的时候,多次测试的结果是,这款模型在视频生成审核非常严格,这要比在sora2中使用同样的提示词生成视频要严格很多,这次模型还在进化中,视频生成效果确实非常逼真,我个人感觉已经超过sora2的模型,我的个人看法,我感觉,只要使用的人越来越多,这个模型的进化速度就越来越快,即梦网页版是测试是,5秒视频消耗的积分是25,每增加5秒加5个积分,最高15秒视频需要消耗75积分,如何大家想要免费使用更多的视频生成,还是去app,首推使用豆包去做,目前来说我使用的最多的还是使用豆包首次图片视频,对于新人来说非常适合不过了
关于即梦和豆包网页版的功能区别
使用豆包网页版,生成视怕不能添加自定义时间,不能选择首尾帧智能多帧,即梦是可以做到多方面的功能选择,当即梦不免费,而豆包是可以免费使用的,大家自行参考
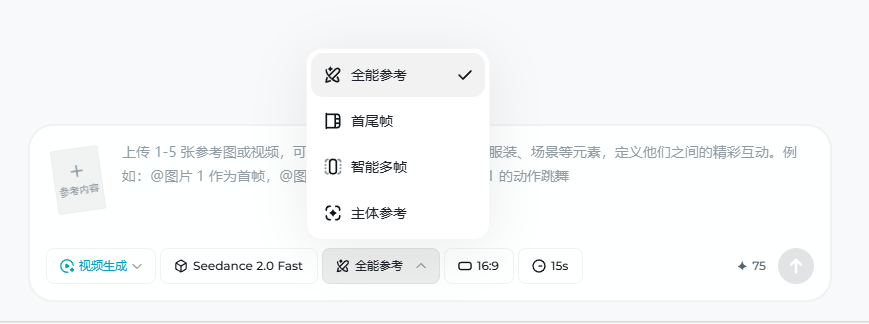
目前来说这两款国产AI可玩性还是非常大的,最后我想告诉很多朋友,国内的AI发展真的是非常卷,大家只要选择适合自己的AI一款就可以了,功能几乎大同小异,主要是国内竞争力太大了,我不知道为什么,更多的是圈钱,在豆包还是可以免费使用的情况下,大家赶紧去体会,去了解AI去接触AI,不要被AI淘汰,当然了你也不会,我们目前缺乏的东西太多了,我不希望看到的是大家都在为了内卷去消耗自己的时间,如何靠AI去赚钱是另一回事,我们这里不讨论这些,因为现在有太多的人非常困难,没有人会去帮你,只有你自己一个人去经历学习,每个人对于AI的理解学习能力都不同,当起点都是一样的,保持你的好奇心让我们一起去探索AI的世界。
创作心法:从“许愿”到“蓝图”
AI不是读心术,它需要清晰、具体、可视觉化的指令。记住三个转变:
- 从抽象到具体:不说“先进的AI”,而说“如活水般流动、重组的数据流”。每个形容词都应有对应的画面。
- 从复杂到聚焦:一个视频最好只讲述“一个主体”和“一个核心动作”。想表现宏大的未来城市?可以用一个市民的清晨通勤来串联。
- 从被动到主动:利用模型的“@引用”功能,上传你心仪的未来建筑、服装设计图作为参考,能极大提升生成画面的可控性和风格一致性。
未来并非单一图景,它是所有可能性的总和。你此刻写下的提示词,就是为其中一种可能性按下快门。现在,复制上面的模板,去生成你的第一帧未来吧。你会惊讶于,当想象力有了精准的坐标,AI便能为你呈现何等壮丽的景象。